
結果就是這個簡單的小網頁《司改國是 2017 - 提案闖天關》,把歷次會議中所有的提案整理成結構化資料後,用視覺化的方式呈現,看能不能方便委員們追蹤(a.k.a. 找出哪些提案被搓掉 XD)
 |
| 原本叫「議題履歷」,但「提案闖天關」應該比較好記 XD |
前陣子 開放政府圈業力引爆 後,吟遊詩人我側面觀察這議題,感覺開放資料的推動大概有兩種門檻。第一種門檻是議題本身太抽象、不好理解,不理解就無從評判政策好壞,於是政治人物只要堆砌關鍵字,就可以輕鬆唬爛過去。第二種門檻是目前可以參考的案例似乎不太夠,即使有心想做,可能也很難想像具體來說該怎麼開始做,或者做完到底對人類世界有什麼幫助。
這個月初 北市資訊局長在 COSCUP 分享他們的開源計畫,從 演講的內容 看來,政府的程式碼開源這件事情,目前處於從無到有、開疆拓土的階段,講者會後提到 現階段需要的是「累積成功案例」——開放資料看起來也剛好處在類似的情況。這種時候,如果能做一些具體的、從上游資料產生到下游應用開發的完整案例,也許就可以幫助其他人理解「如果做好 data,那可以產生什麼應用」或者「要看到這樣的應用產生,必須先怎樣做 data」,同時也可以慢慢累積實做經驗,讓有心想做的人瞭解「所以有什麼是我可以做的」。
實驗涵蓋的範疇
至於生產鏈中間段的隱私保護、資料數位化管理、政府資訊公開等,由於司改國是的資料中剛好沒什麼個資,且主辦單位跟外包廠商也已經下了不少苦功,把所有資料以數位化方式儲存、放在公開網站上,因此我只要撿現成的就好了,實驗的內容就先略過這些環節 lol
實驗步驟
開發 open data 應用的第一件事,就是先搞清楚有哪些 data 可以玩。
步驟一、資料大盤點
司改國是會議雖然有把所有資料放在官網上,但並沒有一個集中的資料清單,如果想搞清楚總共有哪些 data,要先把整個官網翻過一遍用工人智慧下去盤點,才能把資料清單整理出來... 總之是件曠日廢時的苦差事。好在 whisky 因為擔任第四組委員的關係,已經先 把全部組別的資料都盤點過 了,我就樂得當伸手牌,直接 A 來用 XD
第二件事,是把這些清單上列出的資料變成機器可讀的格式,才可以直接餵給程式。這個步驟,也就是所謂的資料結構化。
那麼,這個結構化的資料該長啥樣勒?要拆成幾張資料表?每張表有哪些欄位?欄位要取什麼名字?裡面要存成 hash 還是 array?動手做資料結構化之前,得先釐清這些具體的規格。
換句話說,要做資料結構化,得先設計出一套合身的 data model 來。
步驟二、設計資料模型
data model 是人類用來描述世界的其中一種方式。
詩詞文章是人類用文字來描述世界,繪畫是人類用圖像來描述世界,歌曲是人類用聲音來描述世界... data model 則是人類用資料解構的方式來描述世界。設計一套好的 data model,就跟寫一篇好文章、畫一張好圖、寫一首好歌一樣,必須先瞭解我們想描述的東西,本質到底是什麼。所以,設計司改國是會議的 data model 之前,要先花點心思摸清楚司改國是會議的本質。
司改國是會議的組成有兩塊:一是司法改革,屬於一種專業領域、議題;二是國是會議,屬於一種審議、討論的形式。這兩件事物本質截然不同,互不隸屬、也互不影響,因此描述它們的時候,需要兩套獨立的 data model。
國是會議的 data model 相對單純,畢竟不管什麼形式的審議,都會有場次、主題、發言紀錄、參考資料等共通的內容。當然,站在審議技術的立場來看,不同審議形式的用途跟功能差異極大;但站在資料解構的立場來看,國是會議跟憲動盟草根論壇兩者的資料形態是大同小異的。因此 data model 的設計方式,就直接參考之前草根論壇的作法,簡單講,把會議記錄裡面出現的內容分門別類整理好,就可以了。
至於司法改革的 data model 就難了。這種 domain knowledge 類型的事物,要先理解該領域的知識樹大概長什麼樣子,才有辦法掌握到它的本質,也才能進一步解構它、用資料模型描述它。在 whisky 提供的資料海中泡老半天以後,決定借用 五力分析 的視角來替司法改革的知識地圖打底。
在各式各樣的產業分析方法中,五力分析側重的是影響整體動態平衡的各種因素,用一個軸向看生產鏈內部環境(上游供應商、下游購買者),另一個軸向看生產鏈外部環境(同業競爭者、異業替代品),視野涵蓋的範圍寬廣且完整。用五力分析的概念看司法改革議題的話,司法體系生產鏈的內部除了業界本身以外,還包括上游的司法養成教育、以及下游的受影響民眾,外部環境則包括上游的公民意志(在極權國家,公民意志要替換成獨裁者的意志)、以及下游的社會效應。在這個近似於五力分析的視角之下,司改知識地圖的底稿長這樣:

底圖出來後,先是試著把司改國是會議各組的主題對應上去:

結果聽 whisky 講才知道,這五個分組主題只是參考用,有些沒人要的議題會被丟包去別組(額)所以實際上要看這 21 個細部的子議題:

結果一大票子議題都在中間跟右邊,擠成這樣幾乎等於沒分類 www 還好 whisky 又掏出一張 英國人做的神圖 ,把司法業務的每個環節攤開來,各自對應到體制內外的組織和使用者,換句話說,剛好可以把底圖裡面的「司法業界」跟「受影響民眾」這兩區再切細:
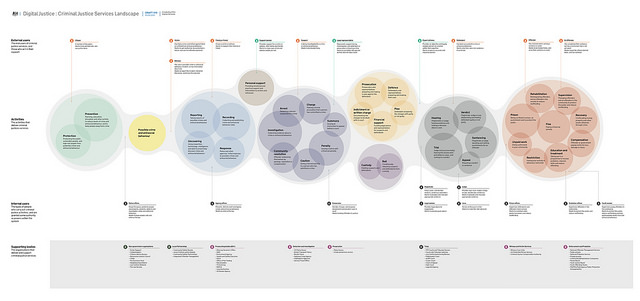
到這邊,司法改革議題的知識地圖浮現,差不多就是我的偽五力分析圖加上 whisky 找的英國人神圖。
有知識地圖以後,終於可以來做司改議題的 data model 了。我目前是沿用英國人神圖的形式,以業務群組為基本單位,每個業務群組會對應到多個單項服務、體制內使用者、體制外使用者、以及組織。詳情可參考這個 json 格式的檔案 ,裡面的中文是我亂翻的,如果有人要拿去用的話,記得先請專業的校對 w
步驟三、產品企畫
data model 有了,但要做成什麼應用,才能讓大家有感勒?跟 whisky 亂聊產生兩個 idea:第一個是《議題導遊》,使用者只要在知識地圖上到處點,就可以看到各種相關的會議資料,用來協助一般人瞭解議題。第二個是《議題履歷》,使用者只要在選單上到處點,就可以看到自己組別的議題狀態,用來協助委員們追蹤議題。
雖然對大會來說,做《議題履歷》可能比較有實際的幫助,但當時距離 8/12 週六的總結會議剩下不到一個禮拜,data model 雖然有了,但還要按圖施工才能真的結構化,而產品除了 idea 外還沒有 user journey 或 wireframe 等任何具體的進展... 各種不確定因素下,菜鳥我完全不覺得自己能在幾天內做出可以動的 prototype,所以就很乾脆地放棄這題目了。畢竟,委員們如果要追蹤提案,直接手動做一份文件可能還比較快。
總之,我就以《議題導遊》為目標,開始做資料結構化跟做網站企畫。
那幾天 whisky 把我跟雨蒼拉到一個聊天群組,就順便約了禮拜四去司改會 cowork。結果去了司改會,遇到 miffy,她現場掏出連雨蒼都不知道的 google spreadsheet,裡面有大把現成的結構化資料(驚)原來各組的所有提案,miffy 她們都有手動製表註記狀態... 看了看,發現雨蒼之前提供的資料,加上 miffy 現場掏出來的資料,湊起來做《議題履歷》剛剛好耶 OwO
所以我就在司改會當場畫好 wireframe,改做《議題履歷》啦 \^o^/
步驟四、程式開發
有現成資料後《議題履歷》做起來飛快,隔天早上就先推了一版到 github pages 上。原本打算推完就去睡覺,結果看到布丁在臉書上指出配色問題,忍不住動手去改一下,改一改想說那順便把功能做完好了... 結果做完以後,就到下午了,好久沒熬夜成醬子,有種瀕死的感覺 ((O_O))
做完隔天,司改國是總結會議轟轟烈烈地開始,然後轟轟烈烈地結束了。看著臉書上的各種烽火連天,我相信《議題履歷》在這場會議中是完全沒用武之地的,哈哈。
後來發生一樁悲劇,就是雨蒼試圖把《議題履歷》demo 給別人看的時候,網頁在手機上打不開,一載入就卡死 www 我才想到那不到一天寫出來的爛 code 完全沒有考慮效能,所以這禮拜又花了三四天研究,總之,現在用手機開應該沒問題了,桌機的載入速度應該也會快很多才是。
題外話,網站名稱不叫《議題履歷》是因為三年前做過一個很類似的東西,追蹤立院議案進度用的,叫做 《議案闖天關》 ,名字很可愛(自己說!)但最後沒上 production 感覺有點可惜,想說就讓這名字在這邊復活好了,因此網站名稱就變成 《提案闖天關》 啦 lol
實驗心得
這次最大的收穫,是似乎發現了一條推廣 open data 的蹊徑 XD
百年一見的 open data 練武奇才:審議
前面說過,一般的政府資料,從源頭產生到最後結構化釋出,要經過層層關卡,在這中間,拿任一個環節做實驗,都可能給相關工作人員帶來麻煩。
但這次拿司改國是會議的資料做實驗,除了隊友 whisky、雨蒼、miffy 以外,完全沒有影響到其他任何人喔!揪瞇 ^.< 因為審議資料的生命旅程,有幾個特別的地方。首先,這些資料大多數情況下生來就不涉及隱私,因此不需做去識別化之類的額外加工,就可以直接釋出;其次是資料本身全都是人類可讀的內容,不像數據形態的資料可能要處理統計偏誤的問題,或者需要額外的解釋才能呈現出有意義的資訊,資料裸身見客,需要 debug 的環節也跟著變少;再來是每場審議都會在一定時間內結束,不需要常態性維護任何文件或流程,因此,在審議會議中嘗試新的作法,沒有和之前的場次不相容的問題,也不會造成後續場次的包袱。
也就是說,審議的資料一來處理難度低、好入門,二來處理自由度高、好把玩,用來做 open data 的示範案例蠻適合的。未來,如果有人想做輕量的 open data 範例,拿審議當主題也許是個不錯的主意。
歷久彌新的國民編輯後台:google spreadsheet
幾年前菜鳥我做 HackFoldr 2.0,人生中第一次接資料就接 google spreadsheet。原本想說俺進步了,應該要從更厲害的地方接資料才對!
結果前陣子發生了一件讓我十足意外的事情,就是先前做的 OCF 官網 ,維護人員決定把資料編輯介面從 yml 改回 google spreadsheet。無獨有偶,這次司改國是會議 miffy 跟雨蒼她們整理的大量資料也都是用 google spreadsheet 編輯,我才驚覺自己太小看它了。
仔細想想,gsheet 可能是目前市面上最友善的資料編輯介面了。功能齊全服務穩定不說,任何稍微會文書處理的人都可以無痛上手,而且這年頭幾乎每個人都有現成的 google 帳號,不用特別設定,連結打開就可以開始作業。此外,欄位間的移動比 web form 快,呈現方式比 yml 或 markdown 直覺,可以大量編輯又不用特別記什麼語法,各種方便。
不過 gsheet 的死穴是長內容,一大篇文章塞在儲存格裡面會很難閱讀也很難排版。如果遇到長內容的話,可能把本體放在別處,讓 gsheet 存連結會比較方便。
司改國是 data model 的未來發展
實驗最重要的成果,莫過於這個 接資料專用 - 司改國是 2017 gsheet 裡面的資料欄位了。
這些欄位把 whisky 跟司改會 miffy 雨蒼他們整理的資料,都歸納進來,涵蓋範圍算是蠻完整的。底線開頭的欄位是 unique id,reference 到別張工作表用的。司改會替每一場會議、每個議題、每點討論事項,都設計了 unique 的編號,這些命名規則也很有參考價值。unique id 欄位中的「、」字元則是編輯人員約定的分隔符號。
總之,下次有類似會議的話,希望可以一開始就建一個像這樣的表格、然後約定一個類似的編輯規則。這樣把資料接出去做成應用的時候,會快很多,可以直接從 gsheet 匯出資料就好了,就不需要像這次這樣,寫程式前要先花許多時間手工收集資料、整理資料。
前面講過我們有做兩組獨立的 data model,這個 gsheet,就是國是會議的 data model。至於那個千辛萬苦設計出來的、司改議題知識地圖的 data model 勒?因為後來改題目了,所以完全沒用到啊哈哈 XD
其實會改題目,也跟這個知識地圖 data model 的應用難度有關。原本 whisky 想到一個很屌的 idea,用這個知識地圖上的各種詞彙,去替每一筆會議資料下標籤。這能幹嘛呢?你看現在《提案闖天關》的選單,只能依組別分類,但其實,不同組的主題之間並不是壁壘分明,實際上可能同時有好幾組都討論到同一個對象。比方說,如果我想看所有組別裡面討論「檢察官」的提案,要怎麼辦呢?這在目前的《提案闖天關》裡面是做不到的。
這種時候,如果每一筆會議資料都有下標籤,那麼利用標籤,就可以把所有「檢察官」相關的資料撈出來,這樣的結果,應該會比直接對 raw data 做全文搜尋來得乾淨。但後來發現這個工人智慧下標籤的任務實在太過費時費力,一來要下標籤的人本身要懂法律,二來這個人要花時間看完內文,門檻實在太高了,完全不是我能力範圍內做得到的。(這同時也是 Debater 小編的難處:下標籤太苦力了)
踢過這個鐵板後,我們目前的想法是,將來如果有人要做跨組、跨場次的資訊彙整,或者類似《議題導遊》之類的東西,也許可以試試看用知識地圖上的標籤做全文搜尋,也許單純搜尋的結果會很雜亂,也許需要搭配一些語意的工具,或者人工手動調整,但不管怎樣,應該都比完全由人工登錄標籤來得實際。
整體來說,這次的實驗心得有兩個方向可以給大家參考:
1. 如果你是規劃審議活動的人,在籌備階段、討論資料彙整方式的時候,可以參考我們這份 接資料專用 - 司改國是 2017 gsheet 來制訂編輯規則,這樣的話,輸入資料的同時就可以很即時地產生各種網頁呈現,不僅會議期間的資料查閱可以更便利,會後的整理工作也會輕鬆很多。
2. 如果你是專精在特定議題的工作者,平時在彙整議題資料的時候,可以考慮根據該議題的知識地圖,隨手替收集到的資料下標籤,這樣長期累積下來,應該會變成一個很棒的資料庫,將來不管要做成什麼樣的應用,對工程師們來說都會方便很多。
這些欄位把 whisky 跟司改會 miffy 雨蒼他們整理的資料,都歸納進來,涵蓋範圍算是蠻完整的。底線開頭的欄位是 unique id,reference 到別張工作表用的。司改會替每一場會議、每個議題、每點討論事項,都設計了 unique 的編號,這些命名規則也很有參考價值。unique id 欄位中的「、」字元則是編輯人員約定的分隔符號。
總之,下次有類似會議的話,希望可以一開始就建一個像這樣的表格、然後約定一個類似的編輯規則。這樣把資料接出去做成應用的時候,會快很多,可以直接從 gsheet 匯出資料就好了,就不需要像這次這樣,寫程式前要先花許多時間手工收集資料、整理資料。
前面講過我們有做兩組獨立的 data model,這個 gsheet,就是國是會議的 data model。至於那個千辛萬苦設計出來的、司改議題知識地圖的 data model 勒?因為後來改題目了,所以完全沒用到啊哈哈 XD
其實會改題目,也跟這個知識地圖 data model 的應用難度有關。原本 whisky 想到一個很屌的 idea,用這個知識地圖上的各種詞彙,去替每一筆會議資料下標籤。這能幹嘛呢?你看現在《提案闖天關》的選單,只能依組別分類,但其實,不同組的主題之間並不是壁壘分明,實際上可能同時有好幾組都討論到同一個對象。比方說,如果我想看所有組別裡面討論「檢察官」的提案,要怎麼辦呢?這在目前的《提案闖天關》裡面是做不到的。
這種時候,如果每一筆會議資料都有下標籤,那麼利用標籤,就可以把所有「檢察官」相關的資料撈出來,這樣的結果,應該會比直接對 raw data 做全文搜尋來得乾淨。但後來發現這個工人智慧下標籤的任務實在太過費時費力,一來要下標籤的人本身要懂法律,二來這個人要花時間看完內文,門檻實在太高了,完全不是我能力範圍內做得到的。(這同時也是 Debater 小編的難處:下標籤太苦力了)
踢過這個鐵板後,我們目前的想法是,將來如果有人要做跨組、跨場次的資訊彙整,或者類似《議題導遊》之類的東西,也許可以試試看用知識地圖上的標籤做全文搜尋,也許單純搜尋的結果會很雜亂,也許需要搭配一些語意的工具,或者人工手動調整,但不管怎樣,應該都比完全由人工登錄標籤來得實際。
小結
整體來說,這次的實驗心得有兩個方向可以給大家參考:
1. 如果你是規劃審議活動的人,在籌備階段、討論資料彙整方式的時候,可以參考我們這份 接資料專用 - 司改國是 2017 gsheet 來制訂編輯規則,這樣的話,輸入資料的同時就可以很即時地產生各種網頁呈現,不僅會議期間的資料查閱可以更便利,會後的整理工作也會輕鬆很多。
2. 如果你是專精在特定議題的工作者,平時在彙整議題資料的時候,可以考慮根據該議題的知識地圖,隨手替收集到的資料下標籤,這樣長期累積下來,應該會變成一個很棒的資料庫,將來不管要做成什麼樣的應用,對工程師們來說都會方便很多。
實驗成本
整個實驗過程,加上事後的效能調整,也才不到兩個禮拜,看起來輕鬆寫意,但這其實完全是站在巨人肩膀上才可能擁有的速度。如果有人想做類似的實驗,記得先觀察一下整體的前置作業進行到什麼程度,再來決定怎麼配置資源。
實驗所需的前置作業
命名規則設計、編輯流程設計、資料輸入與校正:N 個月(主辦單位、各組委員與記錄人員、官網廠商、whisky、司改會)
實驗本身投入的資源
分析議題:兩天(whisky、et)
資料結構化、《議題導遊》產品企畫:三天(whisky、et)
《提案闖天關》產品企畫、雛形實做:一天(雨蒼、miffy、et)
事後調整效能:三天(et)
這邊要特別提醒,《提案闖天關》網頁雖然可以動,但就只是可以動而已,完全沒有做一般網站正式上線該做的事情(三層測試、瀏覽器相容、響應式設計、無障礙、效能最佳化 etc.),且功能也極盡陽春,連站內搜尋都沒有。現在正在看這篇文章的你,如果本身不是網站開發者的話,請記得千萬不要拿本文的時程規格去要求你的 RD 部門或者外包廠商,那樣絕對會激怒他們,而且會害我被打 o_O 專案的時程、經費、人力,一向只有該專案的開發團隊說的才算數,千萬不要道聽途說,更不要拿我的文章道聽途說,拜託拜託 m(_ _)m
資料結構化、《議題導遊》產品企畫:三天(whisky、et)
《提案闖天關》產品企畫、雛形實做:一天(雨蒼、miffy、et)
事後調整效能:三天(et)
這邊要特別提醒,《提案闖天關》網頁雖然可以動,但就只是可以動而已,完全沒有做一般網站正式上線該做的事情(三層測試、瀏覽器相容、響應式設計、無障礙、效能最佳化 etc.),且功能也極盡陽春,連站內搜尋都沒有。現在正在看這篇文章的你,如果本身不是網站開發者的話,請記得千萬不要拿本文的時程規格去要求你的 RD 部門或者外包廠商,那樣絕對會激怒他們,而且會害我被打 o_O 專案的時程、經費、人力,一向只有該專案的開發團隊說的才算數,千萬不要道聽途說,更不要拿我的文章道聽途說,拜託拜託 m(_ _)m
後記
不知不覺間,g0v 社群也 五歲 了。五年前我看到的景象是許多人很憤怒,但多數人動嘴說、少有人動手做,事情原地打轉,怒氣也無從發洩。當時的氛圍下,g0v 以動手做事為號召,彷彿指出一條明路,顯得格外吸引人。
參與社群幾年後,身邊的景象漸漸反轉,舉目所及,動手的已經比動嘴的多,「talk is cheap, show me the code」成為基礎的美德。身為一個討厭社交的實力至上主義者,這樣的小圈圈是很舒適的,畢竟我對大話的人一向不太有好感。
318 後,跨界專案越來越多,社群 slogan 從「寫程式改造社會」漸漸變成「不只是寫程式改造社會」,動手做事的定義也越來越多元了。寫程式是動手,畫圖是動手,做設計是動手,提企畫也是動手,參與腦力激盪是動手,穿針引線溝通協調是動手,讀資料做研究也是動手——到底怎樣算動手、怎樣算動嘴?中間的界線好像越來越模糊了。
後來因為開發動民主的關係參與了幾次 NGO 的會議,文化衝擊之下,才開始跳脫資訊人立場,找到一個比較宏觀的視角來看待彼此的定位。
老早聽說 NGO 的會議非常可怕。跟資訊人習慣的 30 分鐘 standup 相比,傳說中的 NGO 會議可說是超級冗長,一次可以開好幾個小時,而且還不見得有結論(抖)抱著萬全的心理準備參加憲動盟內部會議後,卻大感意外。兩三個小時的會議時間雖然不算短,但一點都不拖泥帶水,按照事先準備好的議程共筆,交換情報、確認論述、選定作戰方針、制訂行動計畫、工作分配... 一路過關斬將,他們並沒有浪費任何時間。會議所產出的擲地有聲的論述,或者瞻前顧後的政治戰略,絕對是 30 分鐘 standup meeting 無法達成的。
那麼,這些 NGO 的會議,到底算是動手,還是動嘴呢?
為了釐清各種跨界產生的矛盾,去年跟 ipa 一起做了 Blupa 量表 ,裡面幾張圖借用了行銷管理的概念,把產品或專案的生命週期,歸納成分析、規劃、實做、維護四個階段。在 g0v 社群裡,最常見的網站設計、前端工程、後端工程,都屬於實做階段;至於社群裡比較少見的使用者分析、商業模式、資訊架構、框線圖等,屬於企畫階段;而 NGO 們最常做的特定領域的議題研究,則屬於分析階段。
NGO 熟悉的前期工作,往往需要大量溝通討論,而軟體開發者熟悉的後期工作,則多半可以分頭獨立完成——
從這個角度來看,可以發現,重點不在於工作的形態為何,只要讓事情往前推進,不管是需要動嘴巴的收集情報、指出問題、發想概念、提出觀點,或者是需要動手的做文件、做圖、寫程式,都是在 hack,都是在做事情。
前幾天在臉書上看到 一段話 :
談邏輯,必然伴隨著「好辯」,對統治者不利,得予以醜化、壓制、否定掉才行。現在,都已經2017年了。如果說,你仍然認為好辯、高談邏輯,很讓人討厭。那就表示,你已經被成功毒害了。
你是某種很成功的「中華式產品」。
想到之前的自己,也曾在心裡偷偷輕視那些愛動嘴的人,不禁覺得心驚。也許,在軟體開發實做的世界裡,大部分的時候,talk is cheap;但在論述思辨倡議的世界裡,大部分的時候,talk is valuable。
思想,是有價值的。
但很現實的是,如果價值沒被看見,就不會產生影響力。那要怎麼讓思想的價值被看見呢?我目前想得到也做得到的,就是當翻譯機,把議題工作者的思想,轉換成對外行人來說容易吸收理解的形式。翻譯家華的思想後,產生了 Blulu ,翻譯 whisky 的思想後,產生了《司改國是 2017 - 提案闖天關》以及這篇實驗心得文。
但很現實的是,如果價值沒被看見,就不會產生影響力。那要怎麼讓思想的價值被看見呢?我目前想得到也做得到的,就是當翻譯機,把議題工作者的思想,轉換成對外行人來說容易吸收理解的形式。翻譯家華的思想後,產生了 Blulu ,翻譯 whisky 的思想後,產生了《司改國是 2017 - 提案闖天關》以及這篇實驗心得文。
如果說水桶的容量取決於最短的木片,那麼,在這波公民運動的資訊化浪潮中,基礎思辨與資訊技術的整合,或許正是那根最短的木片吧?
接下來,希望可以跟更多資訊人,一起愛上思辨,一起往殖民者最害怕的地方走去——雖然在這陌生的混沌世界裡,肯定會跌跌撞撞、或者鬧出許多笑話來,但只要堅持下去,我們的公民社會肯定會越來越強壯,我們的思想武器,也肯定會發展得越來越精良。
希望台灣國旗在凱道上升起的那天,我們已經把自己鍛鍊成合格的國家主人。
專案資訊
名稱:提案闖天關
副標題:司改國是 2017
程式授權:MIT
資料授權:(要看原本司改國是會議的資料授權是什麼)
文件授權:CC BY-NC 4.0
資料模型授權:CC0
指導:司改國是會議第四組張委員網兇 whisky
協力:司改會雨蒼、miffy
上線網址
程式碼
資料表
協作文件
開發手札
心得報告
對專案有想法的話,歡迎到 OpenData / Taiwan 臉書社團 或者 Talking Data G+ 社團 討論 ^^
本文授權:CC BY-NC 4.0 / ETBlue
這篇心得文竟然寫了五天... (倒地
沒有留言:
張貼留言